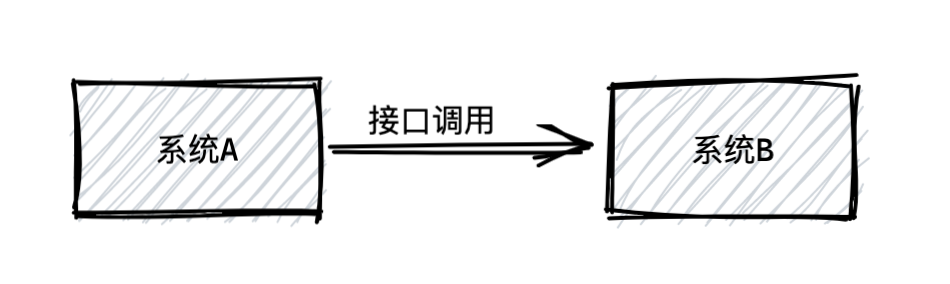
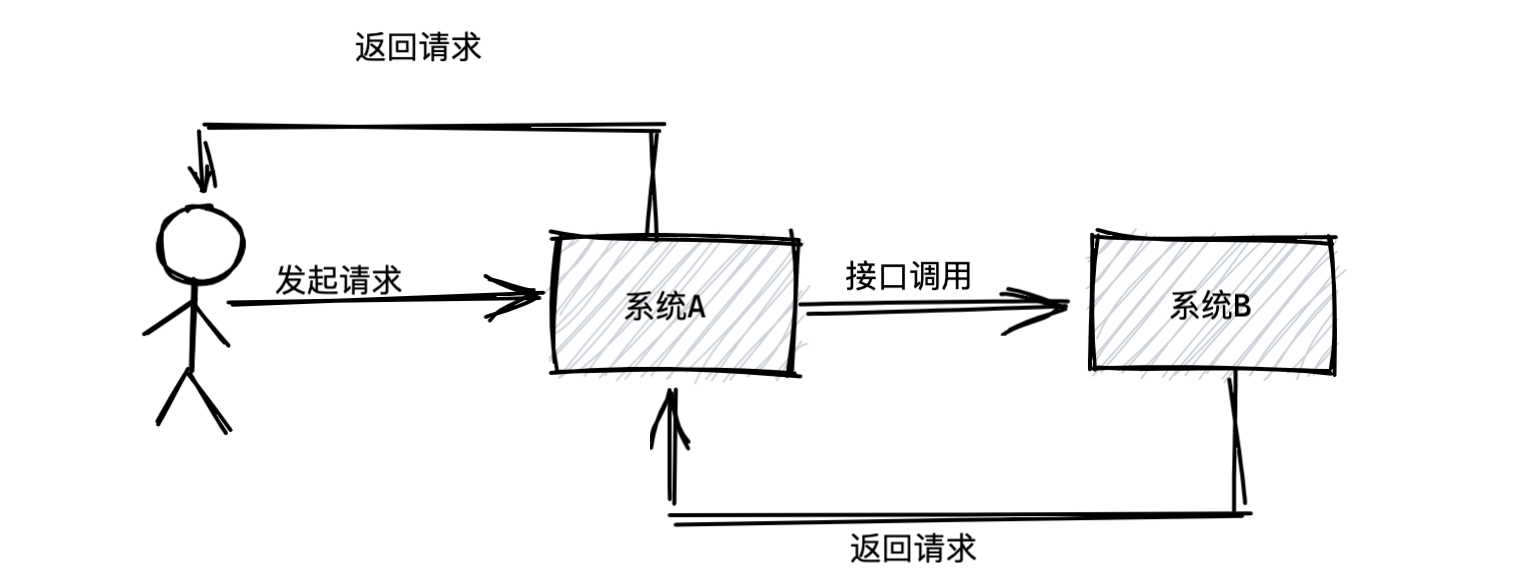
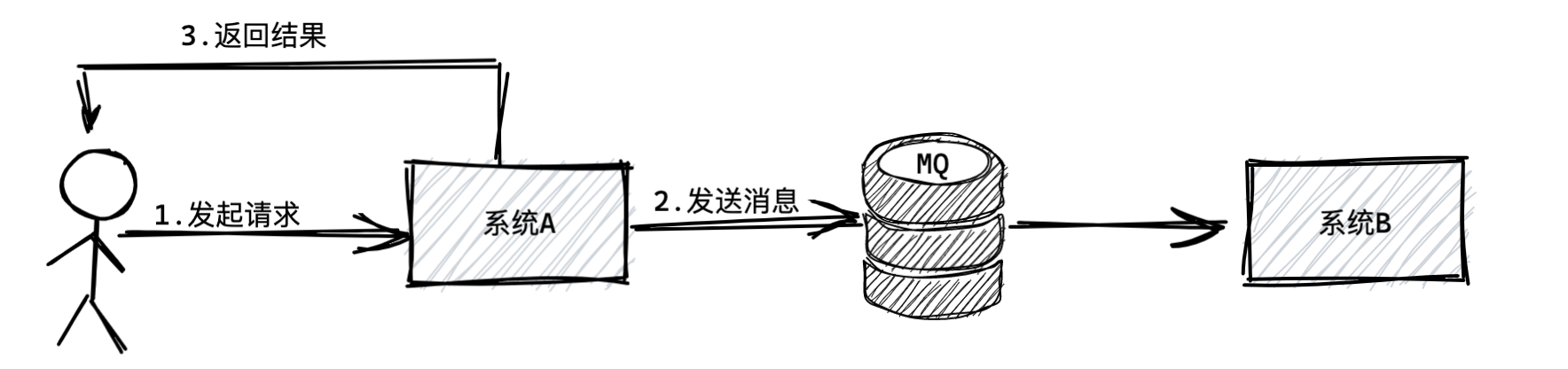
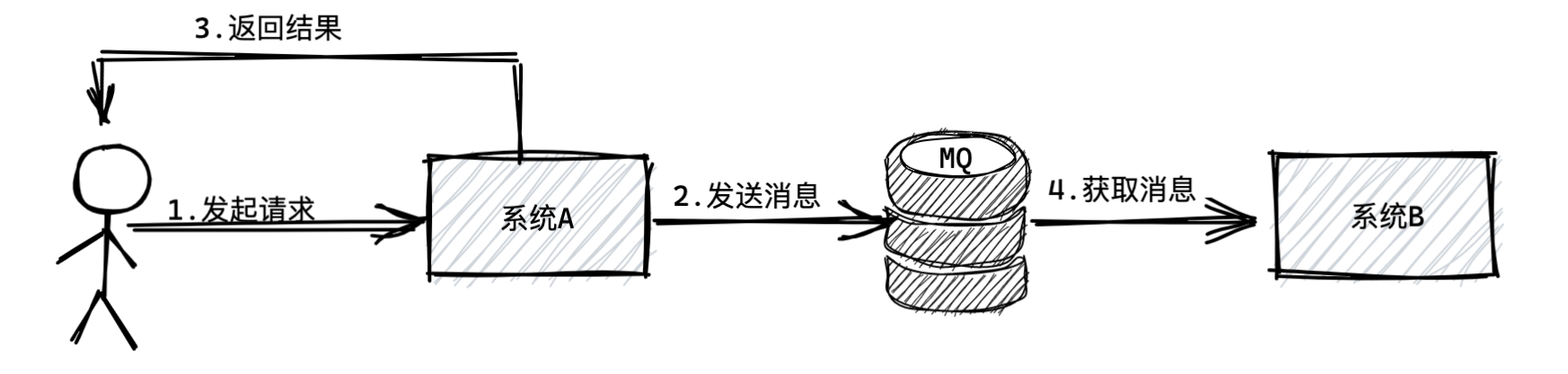
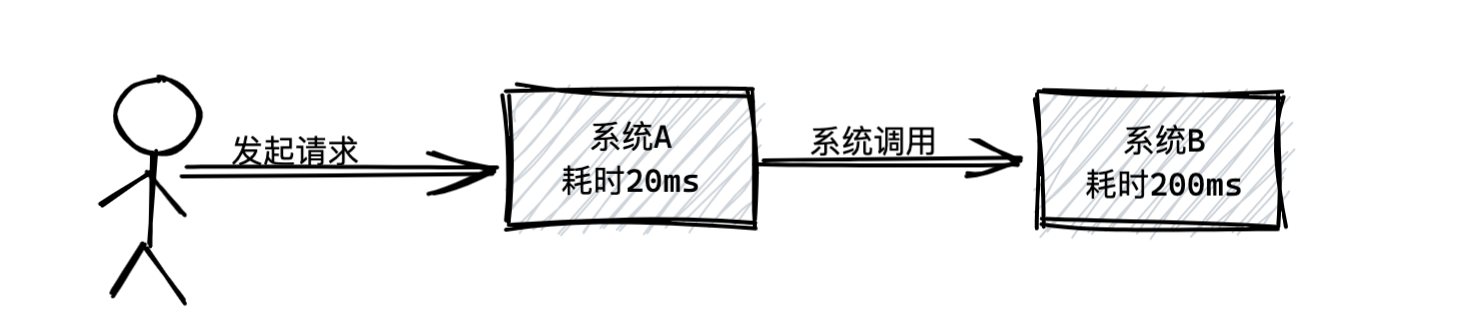
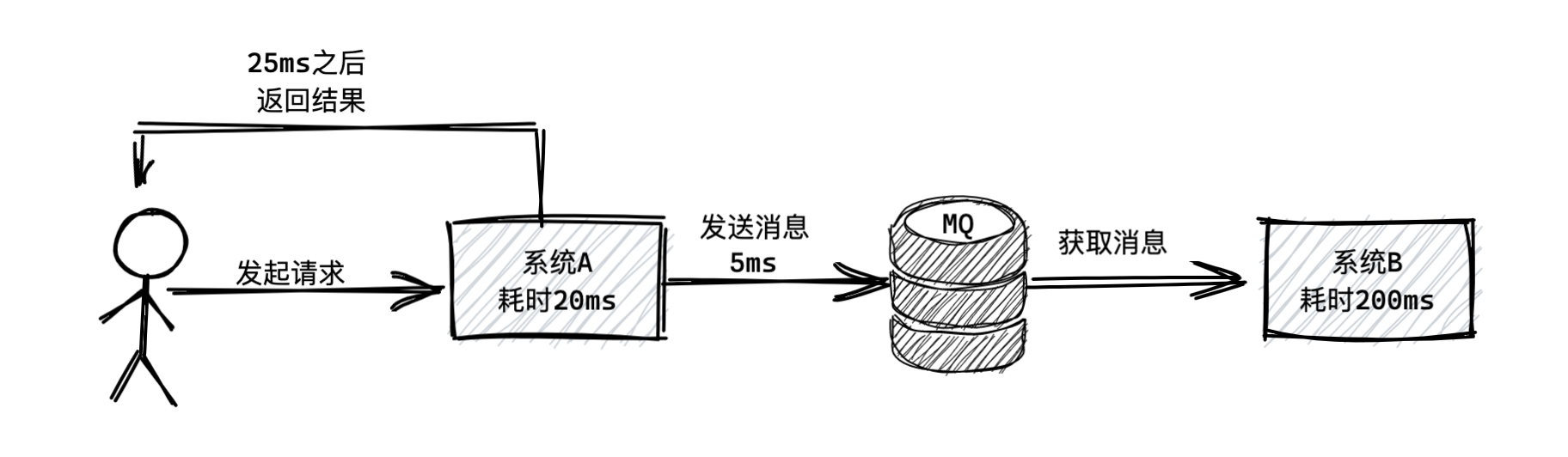
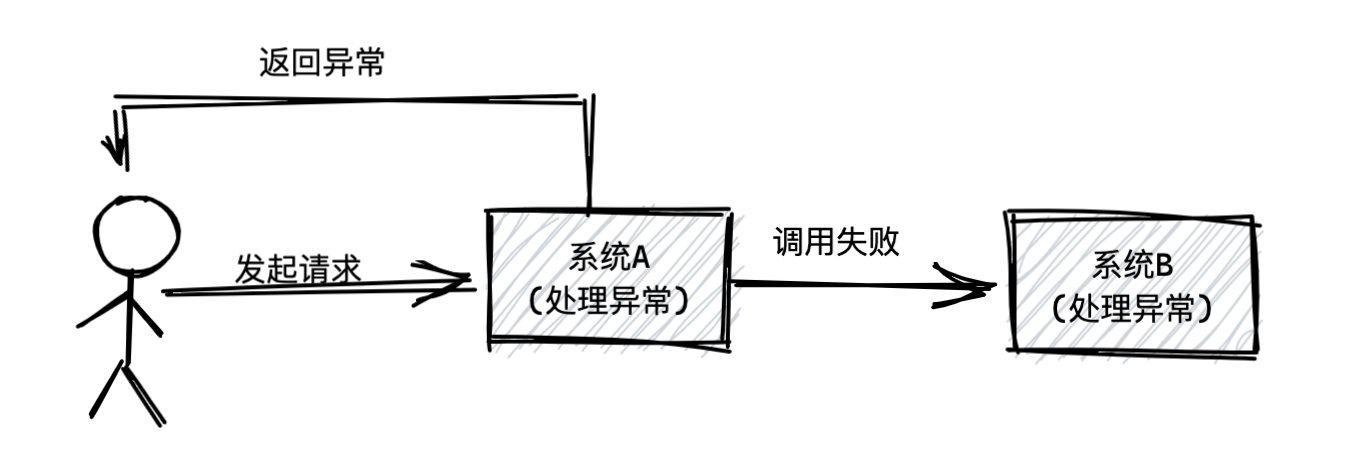
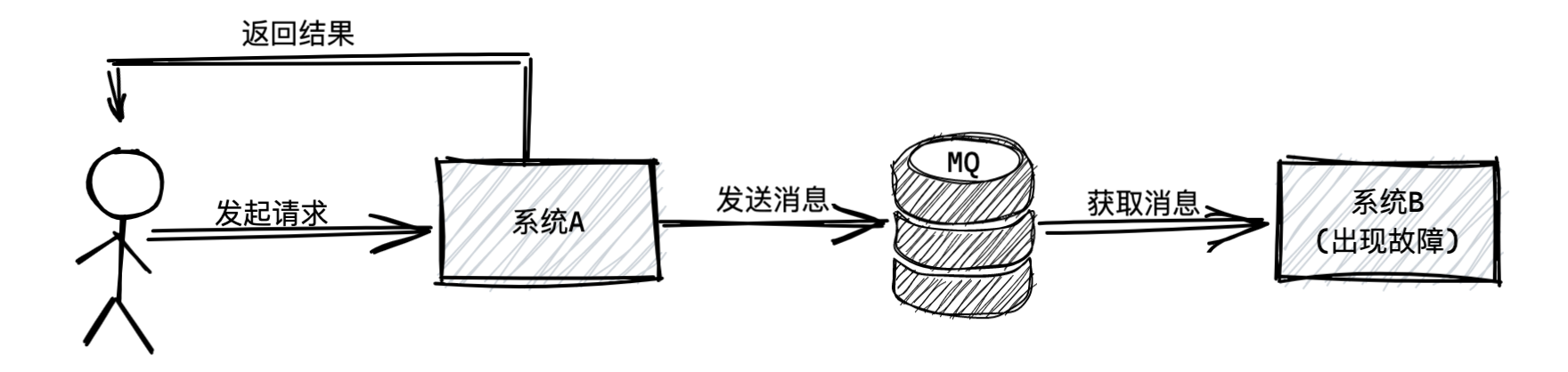
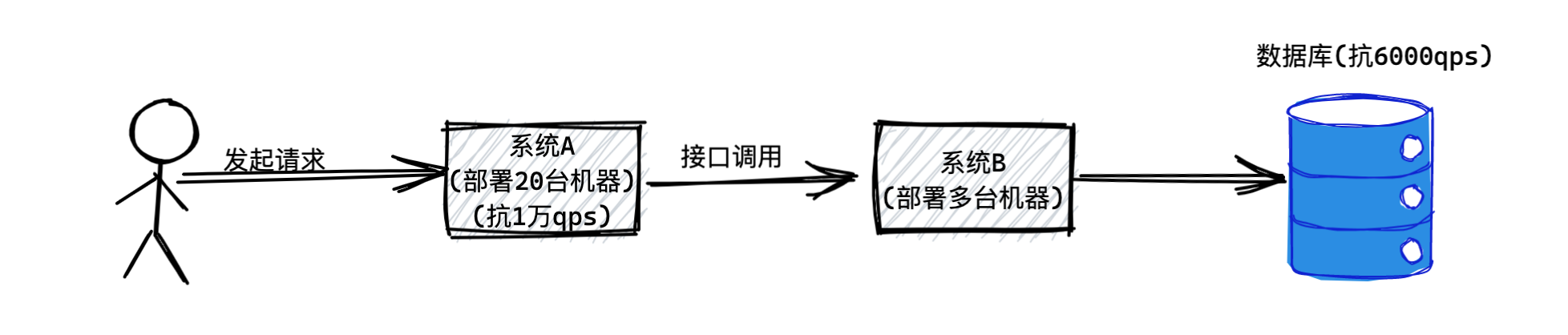
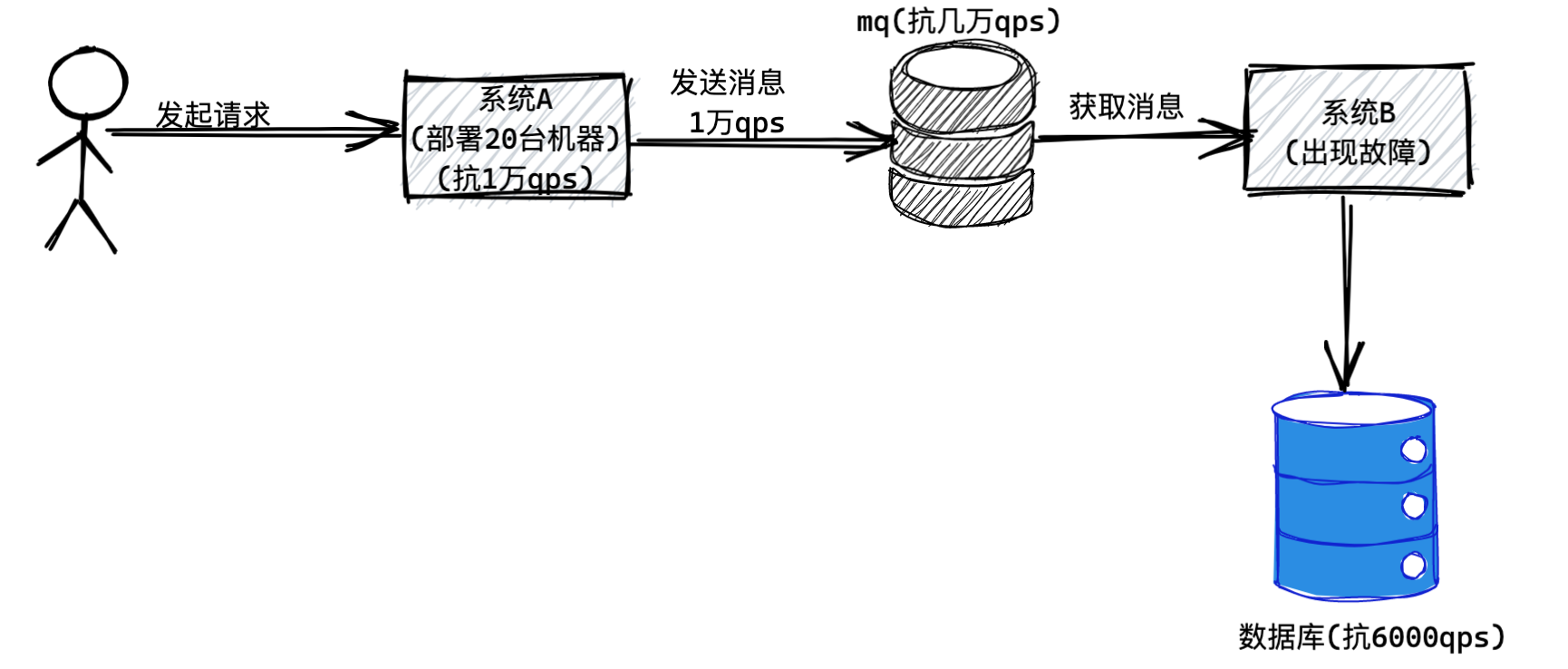
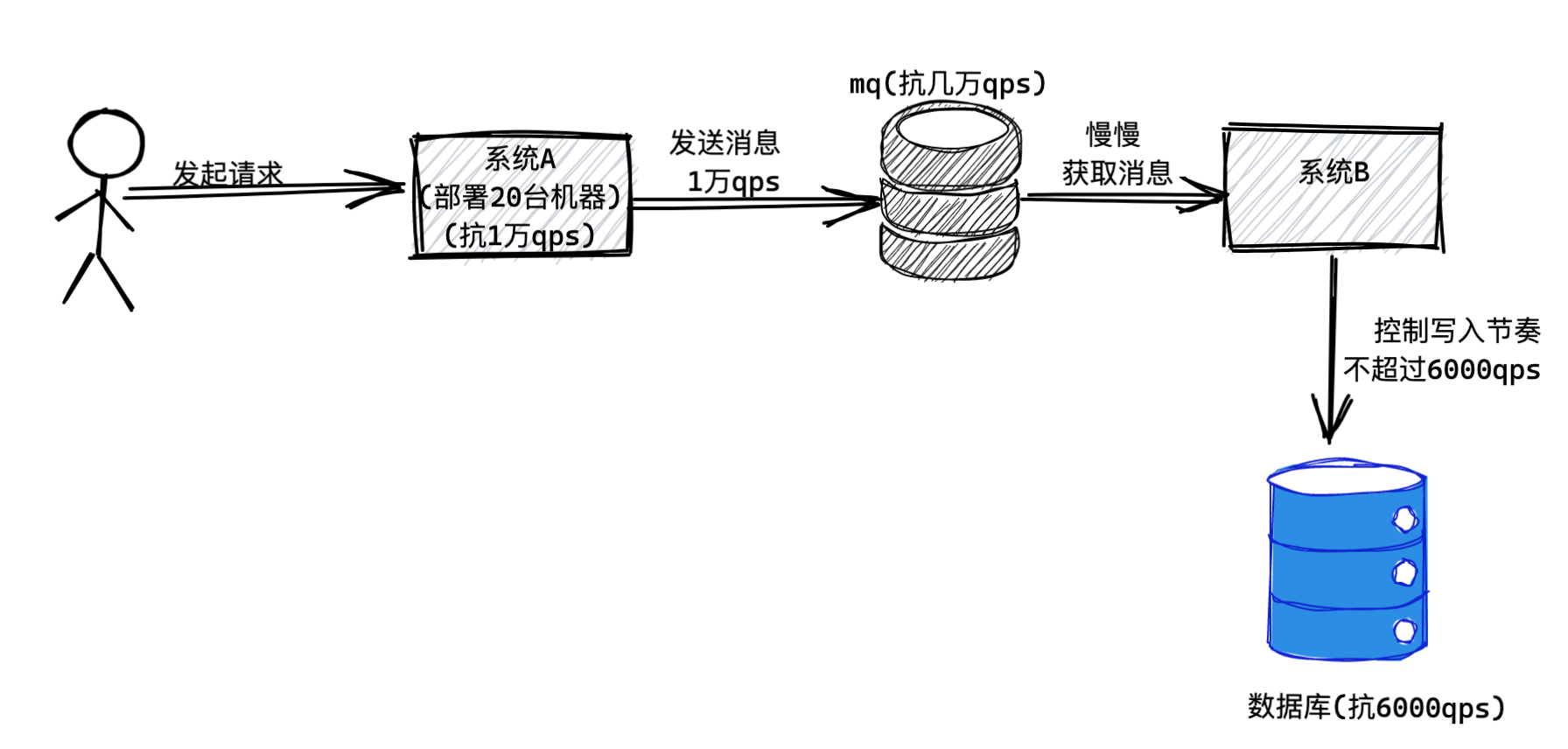
本文主要对比常用的三种中间件优劣势,包含RocketMQ、Kafka、RabbitMQ。
Kafka
优势
- Kafka的吞吐量几乎是行业里最优秀的,在常规的机器配置下,一台机器可以达到每秒十几万的QPS,相当的强悍。
- Kafka性能也很高,基本上发送消息给Kafka都是毫秒级的性能。可用性也很高,Kafka是可以支持集群部署的,其中部分机器宕机是可以继续运行的。
- Kafka技术在各大公司里的使用,基本行业里的一个标准,是把Kafka用在用户行为日志的采集和传输上,比如大数据团队要收集APP上用户的一些行为日志,这种日志就是用Kafka来收集和传输的。
劣势
- Kafka比较为人诟病的一点,似乎是丢数据方面的问题,因为Kafka收到消息之后会写入一个磁盘缓冲区里,并没有直接落地到物理磁盘上去,所以要是机器本身故障了,可能会导致磁盘缓冲区里的数据丢失。
- Kafka另外一个比较大的缺点,就是功能非常的单一,主要是支持发送消息给他,然后从里面消费消息,其他就没有什么额外的高级功能了。所以基于Kafka有限的功能,可能适用的场景并不是很多。
总结
Kafka适用于那种日志适当丢失数据是没有关系的,而且一般量特别大,要求吞吐量要高,一般就是收发消息,不需要太多的高级功能,所以Kafka是非常适合这种场景的。
RabbitMQ
优势
- RabbitMQ的优势在于可以保证数据不丢失,也能保证高可用性,即集群部署的时候部分机器宕机可以继续运行,然后支持部分高级功能,比如说死信队列,消息重试之类的,这些是他的优点。
- 在RocketMQ出现之前,国内大部分公司都从ActiveMQ切换到RabbitMQ来使用,包括很多一线互联网大厂,而且直到现在都有很多中小型公司在使用RabbitMQ,所以说RabbitMQ网上的资料相对多,而且社区非常活跃,更新频率非常快。
劣势
- RabbitMQ的吞吐量是比较低,一般就是每秒几万的级别,所以如果遇到特别特别高并发的情况下,支撑起来是有点困难的。
- RabbitMQ进行集群扩展的时候(也就是加机器部署),比较麻烦。
- 另外还有一个较为致命的缺陷,就是他的开发语言是erlang,国内很少有精通erlang语言的工程师,因此也没办法去阅读他的源代码,甚至修改他的源代码。
总结
现在行业里的一个情况是,很多BAT等一线互联网大厂都切换到使用更加优秀的RocketMQ了,但是很多中小型公司觉得RabbitMQ基本可以满足自己的需求还在继续使用中,因为中小型公司并不需要特别高的吞吐量,RabbitMQ已经足以满足他们的需求了,而且也不需要部署特别大规模的集群,也没必要去阅读和修改RabbitMQ的源码。
RocketMQ
优势
-
RocketMQ的吞吐量很高,单机可以达到10万QPS以上,而且可以保证高可用性,性能很高,而且支持通过配置保证数据绝对不丢失,可以部署大规模的集群,还支持各种高级的功能,比如说延迟消息、事务消息、消息回溯、死信队列、消息积压,等等。
-
RocketMQ是基于Java开发的,符合国内大多数公司的技术栈,很容易就可以阅读他的源码,甚至是修改他的源码。
-
RocketMQ是非常适合用在Java业务系统架构中的,因为他很高的性能表现,还有他的高阶功能的支持,可以让我们解决各种业务问题。
劣势
- RocketMQ也有一点美中不足的地方,就是经过调查发现,RocketMQ的官方文档相对简单一些,但是Kafka和RabbitMQ的官方文档就非常的全面和详细,这可能是RocketMQ目前唯一的缺点。
总结
RocketMQ相对来说比较完美的一个消息中间件,在支撑高吞吐量的同时,而且还支持很多高阶的功能,很适合以Java为技术栈的公司使用。
本文主要对比常用的三种中间件优劣势,包含RocketMQ、Kafka、RabbitMQ。
Kafka
优势
- Kafka的吞吐量几乎是行业里最优秀的,在常规的机器配置下,一台机器可以达到每秒十几万的QPS,相当的强悍。
- Kafka性能也很高,基本上发送消息给Kafka都是毫秒级的性能。可用性也很高,Kafka是可以支持集群部署的,其中部分机器宕机是可以继续运行的。
- Kafka技术在各大公司里的使用,基本行业里的一个标准,是把Kafka用在用户行为日志的采集和传输上,比如大数据团队要收集APP上用户的一些行为日志,这种日志就是用Kafka来收集和传输的。
劣势
- Kafka比较为人诟病的一点,似乎是丢数据方面的问题,因为Kafka收到消息之后会写入一个磁盘缓冲区里,并没有直接落地到物理磁盘上去,所以要是机器本身故障了,可能会导致磁盘缓冲区里的数据丢失。
- Kafka另外一个比较大的缺点,就是功能非常的单一,主要是支持发送消息给他,然后从里面消费消息,其他就没有什么额外的高级功能了。所以基于Kafka有限的功能,可能适用的场景并不是很多。
总结
Kafka适用于那种日志适当丢失数据是没有关系的,而且一般量特别大,要求吞吐量要高,一般就是收发消息,不需要太多的高级功能,所以Kafka是非常适合这种场景的。
RabbitMQ
优势
- RabbitMQ的优势在于可以保证数据不丢失,也能保证高可用性,即集群部署的时候部分机器宕机可以继续运行,然后支持部分高级功能,比如说死信队列,消息重试之类的,这些是他的优点。
- 在RocketMQ出现之前,国内大部分公司都从ActiveMQ切换到RabbitMQ来使用,包括很多一线互联网大厂,而且直到现在都有很多中小型公司在使用RabbitMQ,所以说RabbitMQ网上的资料相对多,而且社区非常活跃,更新频率非常快。
劣势
- RabbitMQ的吞吐量是比较低,一般就是每秒几万的级别,所以如果遇到特别特别高并发的情况下,支撑起来是有点困难的。
- RabbitMQ进行集群扩展的时候(也就是加机器部署),比较麻烦。
- 另外还有一个较为致命的缺陷,就是他的开发语言是erlang,国内很少有精通erlang语言的工程师,因此也没办法去阅读他的源代码,甚至修改他的源代码。
总结
现在行业里的一个情况是,很多BAT等一线互联网大厂都切换到使用更加优秀的RocketMQ了,但是很多中小型公司觉得RabbitMQ基本可以满足自己的需求还在继续使用中,因为中小型公司并不需要特别高的吞吐量,RabbitMQ已经足以满足他们的需求了,而且也不需要部署特别大规模的集群,也没必要去阅读和修改RabbitMQ的源码。
RocketMQ
优势
-
RocketMQ的吞吐量很高,单机可以达到10万QPS以上,而且可以保证高可用性,性能很高,而且支持通过配置保证数据绝对不丢失,可以部署大规模的集群,还支持各种高级的功能,比如说延迟消息、事务消息、消息回溯、死信队列、消息积压,等等。
-
RocketMQ是基于Java开发的,符合国内大多数公司的技术栈,很容易就可以阅读他的源码,甚至是修改他的源码。
-
RocketMQ是非常适合用在Java业务系统架构中的,因为他很高的性能表现,还有他的高阶功能的支持,可以让我们解决各种业务问题。
劣势
- RocketMQ也有一点美中不足的地方,就是经过调查发现,RocketMQ的官方文档相对简单一些,但是Kafka和RabbitMQ的官方文档就非常的全面和详细,这可能是RocketMQ目前唯一的缺点。
总结
RocketMQ相对来说比较完美的一个消息中间件,在支撑高吞吐量的同时,而且还支持很多高阶的功能,很适合以Java为技术栈的公司使用。