1、了解消息中间件之前先了解一下什么是“同步”?
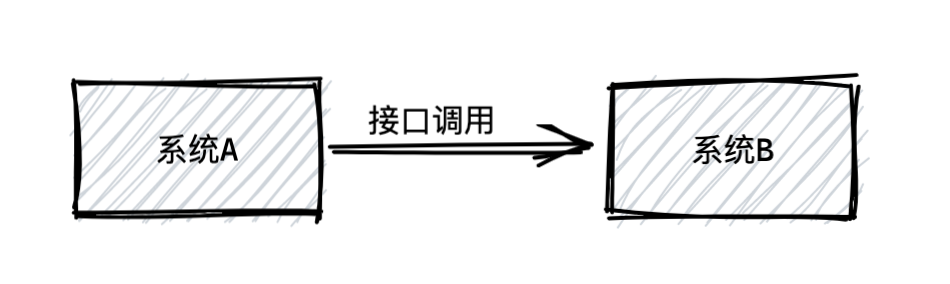
通常业务系统直接的调用如下图所示:
假设系统A收到了一个请求,可能是用户通过浏览器或者APP发起的,这时候系统A收到请求后马上去调用系统B,然后系统B再把返回结果返回给系统A,系统A才能返回给用户。如下图所示:
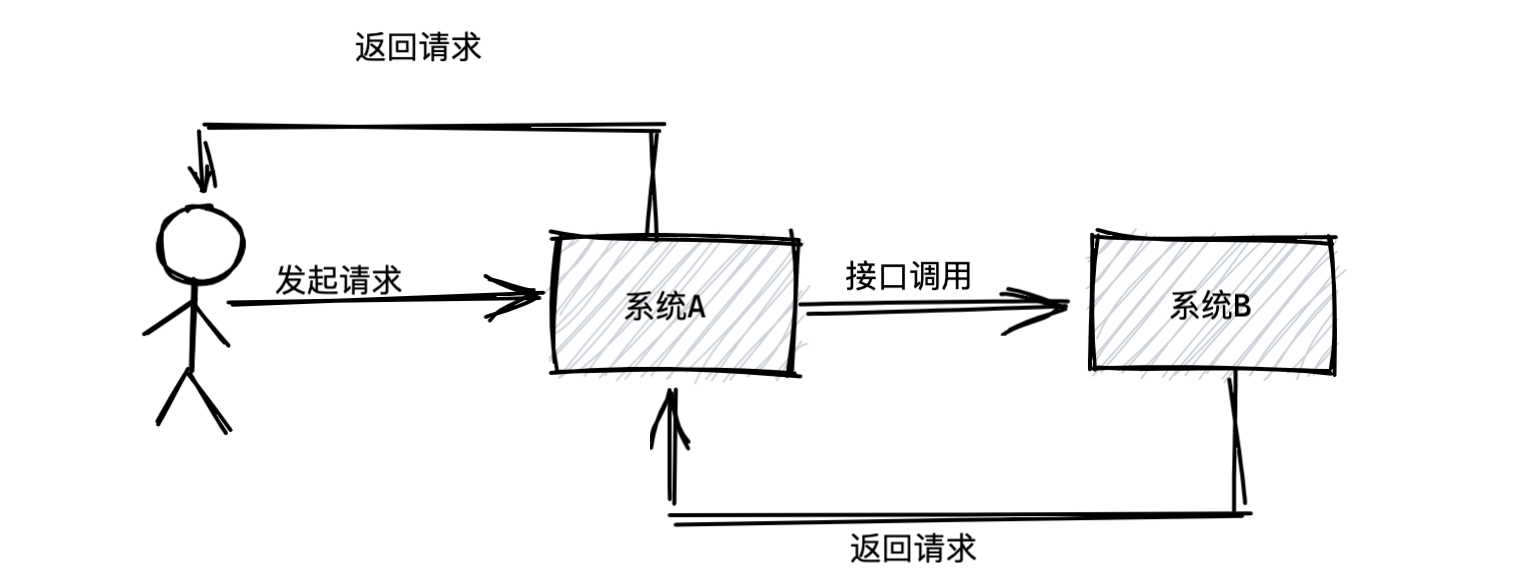
以上就是所谓的**“同步”**调用。这个同步的意思就是各个系统联动都是同步依次进行的,一个系统先动,然后立马带动另外一个系统一起动,最后大家依次干完活以后再返回结果。
2、如何依托消息中间件实现异步?
我们往系统A和系统B之间加入一个消息中间件,简称为“MQ”,也就是消息队列。

加入消息队列之后如何通信呢?
其实就是系统A执行完逻辑后给MQ中发送一条消息,然后就直接把结果返回给用户了。
(注:前提是系统A返回给用户的结果不依赖于系统B的返回结果。假设系统B为短信系统,系统A向MQ发送一条发送短信的消息指令,系统A并不关心短信是否立即发送,只要最终在有效的时间内发送成功就行了。)
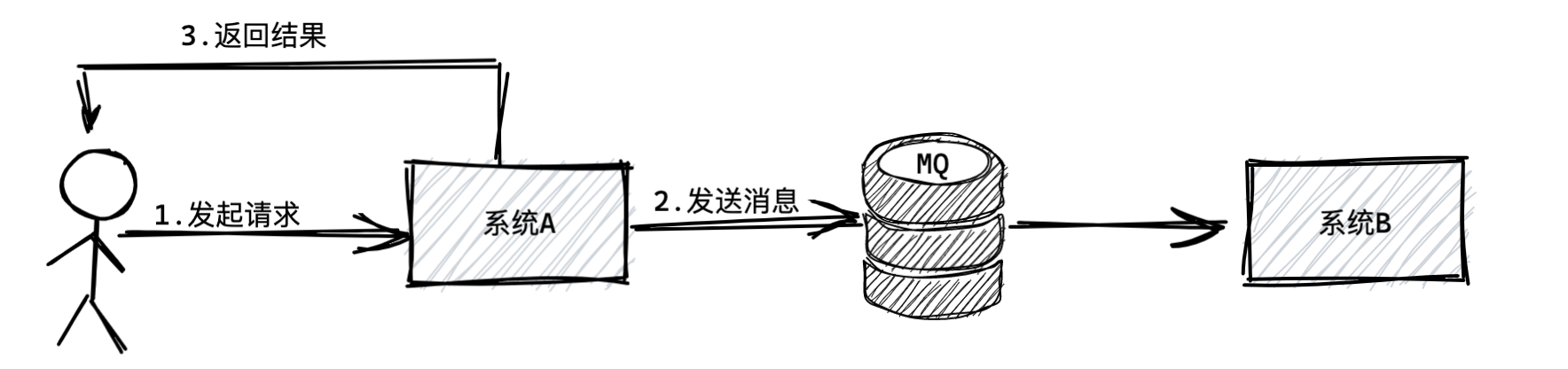
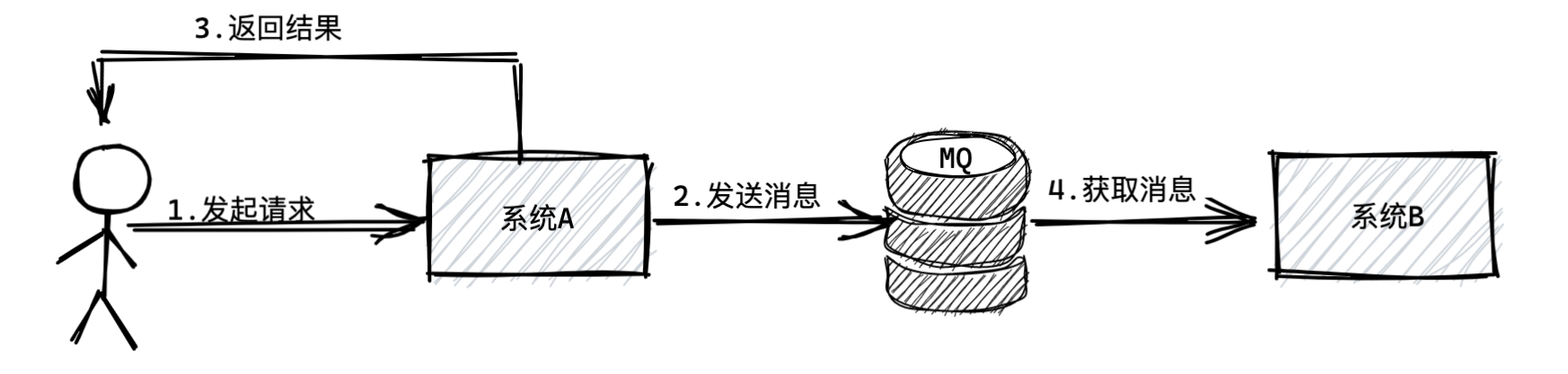
如上图所示,系统B什么时候执行自己的任务呢?
这时候系统B根据自己的情况,可能是系统A投递消息到MQ之后的1秒内,也可能是1分钟之后,多长时间都有可能,不管多长时间,系统B肯定会从MQ里获取到一条属于自己的消息。
3、消息中间件到底有什么用?
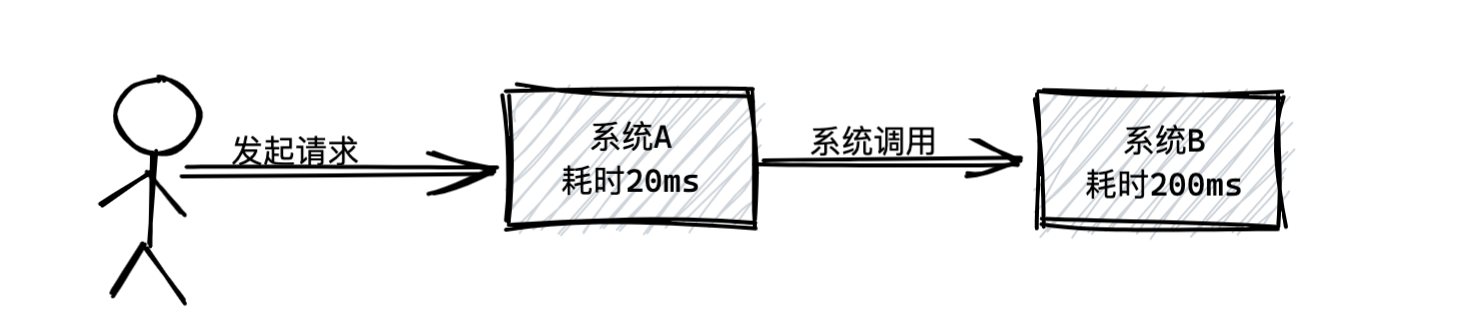
假设系统A要调用系统B干一些事,然后系统A先执行一些操作,需要耗费20ms,接着系统B执行一些操作,需要200ms,所以总共需要220ms。如下图所示:
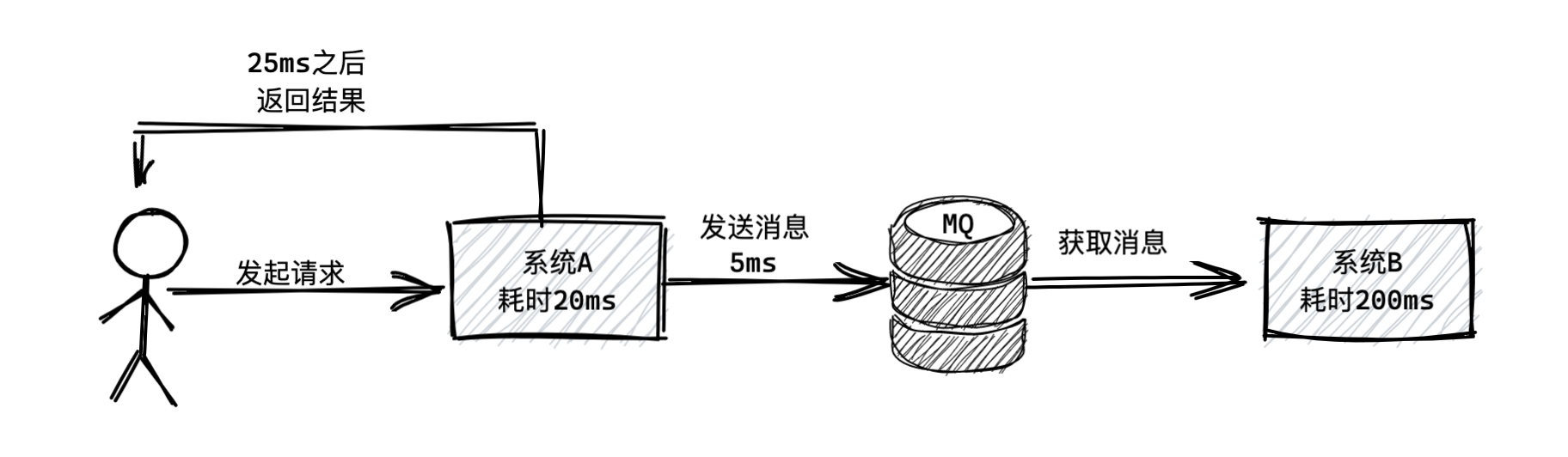
如果在系统A和系统中间加一个MQ呢?
系统A干完自己的事情耗时20ms,然后发一个消息到MQ耗时5ms,然后就直接返回结果给用户,总计耗时25ms。系统B从MQ中获取消息花费200ms和用户就没有关系了。所以用户只需等待25ms就收到结果了。如下图所示:
假设系统A调用系统B出现故障呢?因为系统A调用系统B肯定返回异常,此时系统A是不是也得返回异常给用户?而系统A是不是还要去处理这个异常?
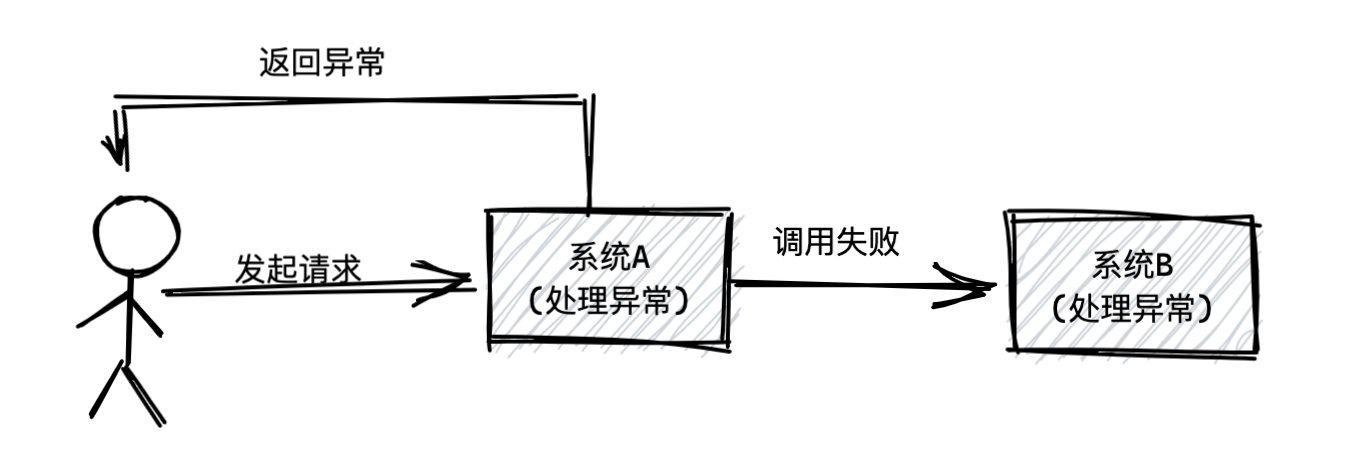
这一切是因为系统A和系统B通过同步调用的模式耦合在一起,所以系统B一旦出现故障,很肯能影响系统A也有故障,而且系统A还得去关心系统B的故障,去处理对应的异常。
如果在系统A和系统B中间加一个消息中间件,系统A就不用关心系统B是否出现故障了,因为那是系统B自己的事,等系统B故障恢复以后,就继续执行它自己的事,此时就对系统A没任何影响了。
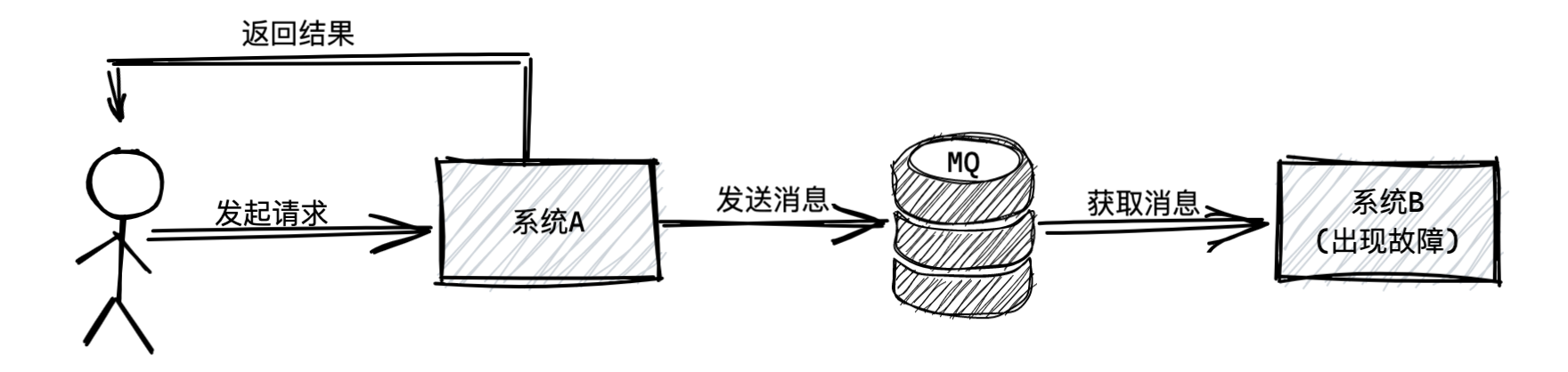
为什么会有这样的效果呢?正式因为通过引入MQ,两个系统实现了异步化调用,也就实现了解耦,所以相互之间并没有任何影响。
5、流量削峰
假设系统A是不操作数据库的,因此只要多部署几台机器,就可以抗下每秒1万的请求,比如部署个20台机器,就可以轻松抗下每秒上万请求。
然后系统B是要操作一台数据库服务器的,那台数据库的上限是接收每秒6000请求,那么系统B无论部署多少台机器都没用,因为他依赖的数据库最多只能接收每秒6000请求。
如下图所示:
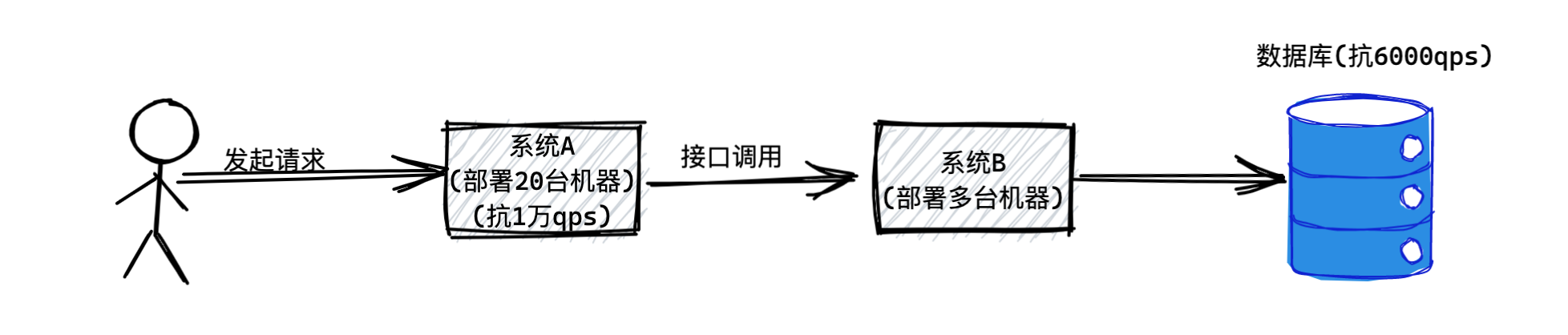
假设现在有1万的QPS请求到了系统A,由于系统A部署了20台机器,所以可以抗住1万QPS。然后系统A会瞬间把1万QPS转发给系统B,假设系统B也抗住了1万QPS,但是系统B对数据库发起了1万QPS的请求,数据库一定会瞬间被压垮。
所以这时如果引入MQ,就可以解决这个问题了。MQ这个技术抗高并发的能力远远高于数据库,同样的机器配置下,如果数据库可以抗每秒6000请求,MQ至少可以抗每秒几万请求。
为什么呢?因为数据库复杂啊,他要能够支持你执行复杂的SQL语句,支持事务等复杂的机制,支持你对数据进行增删改查,听着简单,其实是很复杂的!所以一般数据库单服务器也就支撑每秒几千的请求。
所以只要你引入一个MQ,那么就可以让系统A把每秒1万请求都作为消息直接发送到MQ里,MQ可以轻松抗下来这每秒1万请求。
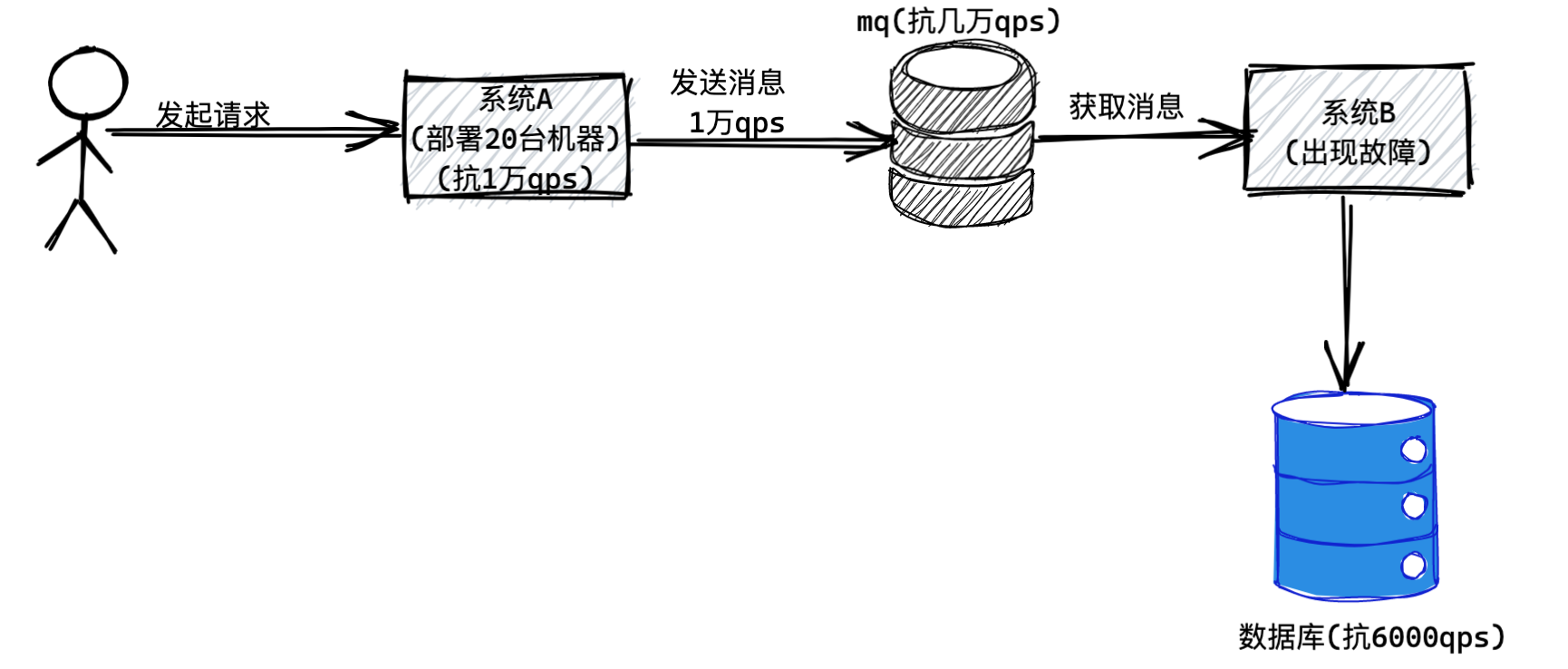
接着,系统B只要慢慢的从MQ里获取消息然后执行数据库读写操作即可,这个获取消息的速度是系统B自己可以控制的,所以系统B完全可以用一个比较低的速率获取消息然后写入数据库,保证对数据库的QPS不要超过他的极限值6000。
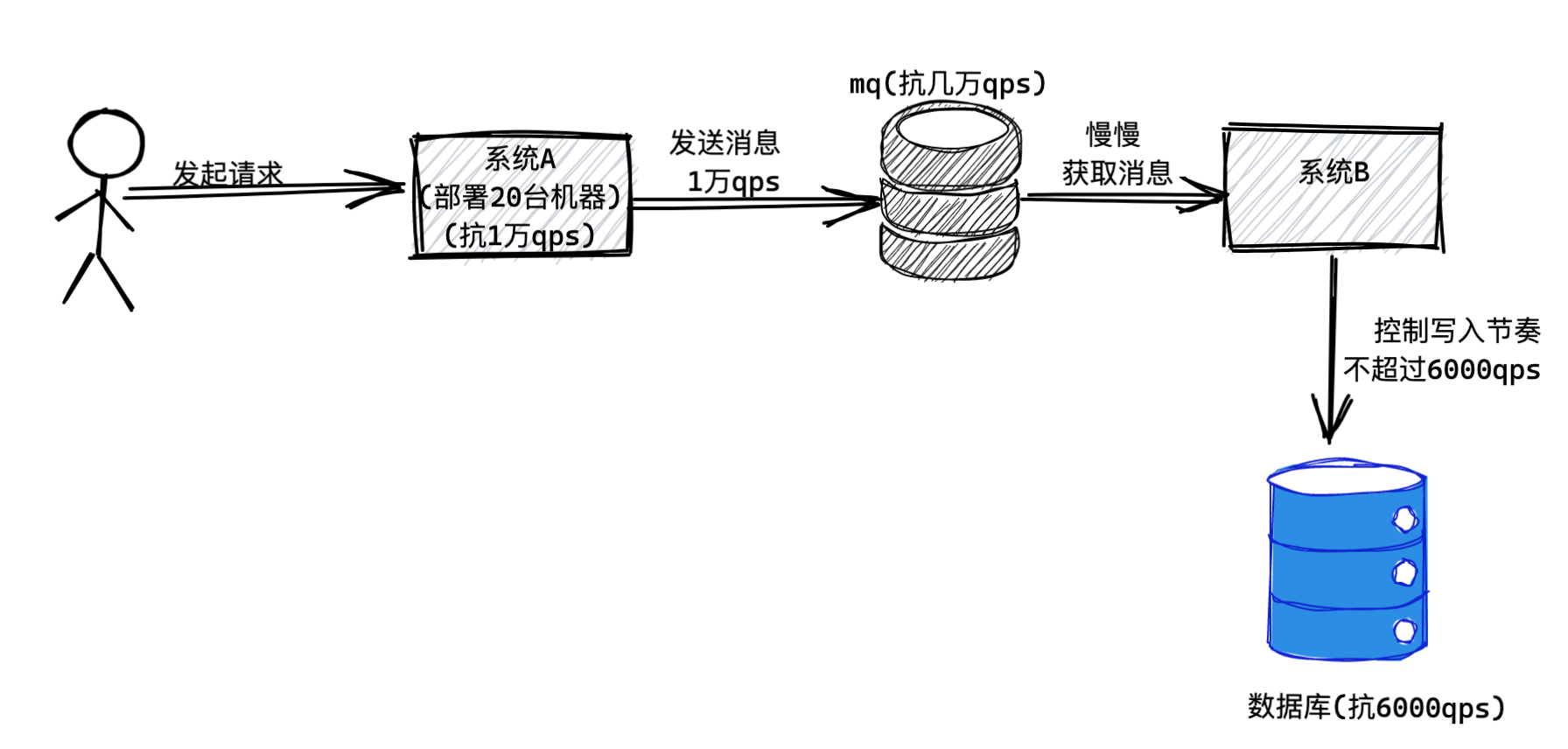
这个时候因为系统A发送消息到MQ很快,系统B从MQ消费消息很慢,所以MQ里自然会积压一些消息,不过不要紧,MQ一般都是基于磁盘来存储消息的,所以适当积压一些消息是可以的。当系统A的高峰过去,每秒可能就恢复到1000 QPS了,此时系统b还是以每秒6000QPS的速度获取消息写入数据库,那么自然MQ里积压的消息就会慢慢被消化掉了。
所以这就是MQ进行流量削峰的效果,系统A发送过来的每秒1万请求是一个流量洪峰,然后MQ直接给扛下来了,都存储自己本地磁盘,这个过程就是流量削峰的过程,瞬间把一个洪峰给削下来了,让系统B后续慢慢获取消息来处理。
6、总结
消息中间件的主要作用就是削峰解耦,提升系统的响应速度。
1、了解消息中间件之前先了解一下什么是“同步”?
通常业务系统直接的调用如下图所示:
假设系统A收到了一个请求,可能是用户通过浏览器或者APP发起的,这时候系统A收到请求后马上去调用系统B,然后系统B再把返回结果返回给系统A,系统A才能返回给用户。如下图所示:
以上就是所谓的**“同步”**调用。这个同步的意思就是各个系统联动都是同步依次进行的,一个系统先动,然后立马带动另外一个系统一起动,最后大家依次干完活以后再返回结果。
2、如何依托消息中间件实现异步?
我们往系统A和系统B之间加入一个消息中间件,简称为“MQ”,也就是消息队列。
加入消息队列之后如何通信呢?
其实就是系统A执行完逻辑后给MQ中发送一条消息,然后就直接把结果返回给用户了。
(注:前提是系统A返回给用户的结果不依赖于系统B的返回结果。假设系统B为短信系统,系统A向MQ发送一条发送短信的消息指令,系统A并不关心短信是否立即发送,只要最终在有效的时间内发送成功就行了。)
如上图所示,系统B什么时候执行自己的任务呢?
这时候系统B根据自己的情况,可能是系统A投递消息到MQ之后的1秒内,也可能是1分钟之后,多长时间都有可能,不管多长时间,系统B肯定会从MQ里获取到一条属于自己的消息。
3、消息中间件到底有什么用?
假设系统A要调用系统B干一些事,然后系统A先执行一些操作,需要耗费20ms,接着系统B执行一些操作,需要200ms,所以总共需要220ms。如下图所示:
如果在系统A和系统中间加一个MQ呢?
系统A干完自己的事情耗时20ms,然后发一个消息到MQ耗时5ms,然后就直接返回结果给用户,总计耗时25ms。系统B从MQ中获取消息花费200ms和用户就没有关系了。所以用户只需等待25ms就收到结果了。如下图所示:
假设系统A调用系统B出现故障呢?因为系统A调用系统B肯定返回异常,此时系统A是不是也得返回异常给用户?而系统A是不是还要去处理这个异常?
这一切是因为系统A和系统B通过同步调用的模式耦合在一起,所以系统B一旦出现故障,很肯能影响系统A也有故障,而且系统A还得去关心系统B的故障,去处理对应的异常。
如果在系统A和系统B中间加一个消息中间件,系统A就不用关心系统B是否出现故障了,因为那是系统B自己的事,等系统B故障恢复以后,就继续执行它自己的事,此时就对系统A没任何影响了。
为什么会有这样的效果呢?正式因为通过引入MQ,两个系统实现了异步化调用,也就实现了解耦,所以相互之间并没有任何影响。
5、流量削峰
假设系统A是不操作数据库的,因此只要多部署几台机器,就可以抗下每秒1万的请求,比如部署个20台机器,就可以轻松抗下每秒上万请求。
然后系统B是要操作一台数据库服务器的,那台数据库的上限是接收每秒6000请求,那么系统B无论部署多少台机器都没用,因为他依赖的数据库最多只能接收每秒6000请求。
如下图所示:
假设现在有1万的QPS请求到了系统A,由于系统A部署了20台机器,所以可以抗住1万QPS。然后系统A会瞬间把1万QPS转发给系统B,假设系统B也抗住了1万QPS,但是系统B对数据库发起了1万QPS的请求,数据库一定会瞬间被压垮。
所以这时如果引入MQ,就可以解决这个问题了。MQ这个技术抗高并发的能力远远高于数据库,同样的机器配置下,如果数据库可以抗每秒6000请求,MQ至少可以抗每秒几万请求。
为什么呢?因为数据库复杂啊,他要能够支持你执行复杂的SQL语句,支持事务等复杂的机制,支持你对数据进行增删改查,听着简单,其实是很复杂的!所以一般数据库单服务器也就支撑每秒几千的请求。
所以只要你引入一个MQ,那么就可以让系统A把每秒1万请求都作为消息直接发送到MQ里,MQ可以轻松抗下来这每秒1万请求。
接着,系统B只要慢慢的从MQ里获取消息然后执行数据库读写操作即可,这个获取消息的速度是系统B自己可以控制的,所以系统B完全可以用一个比较低的速率获取消息然后写入数据库,保证对数据库的QPS不要超过他的极限值6000。
这个时候因为系统A发送消息到MQ很快,系统B从MQ消费消息很慢,所以MQ里自然会积压一些消息,不过不要紧,MQ一般都是基于磁盘来存储消息的,所以适当积压一些消息是可以的。当系统A的高峰过去,每秒可能就恢复到1000 QPS了,此时系统b还是以每秒6000QPS的速度获取消息写入数据库,那么自然MQ里积压的消息就会慢慢被消化掉了。
所以这就是MQ进行流量削峰的效果,系统A发送过来的每秒1万请求是一个流量洪峰,然后MQ直接给扛下来了,都存储自己本地磁盘,这个过程就是流量削峰的过程,瞬间把一个洪峰给削下来了,让系统B后续慢慢获取消息来处理。
6、总结
消息中间件的主要作用就是削峰解耦,提升系统的响应速度。