这里主要的性能目标是可伸缩性,即在大部分情况下,即使,或特别在同步器有竞争的情况下,稳定地保证其效率。在理想的情况下,不管有多少线程正试图通过同步点,通过同步点的开销都应该是个常量。在某一线程被允许通过同步点但还没有通过的情况下,使其耗费的总时间最少,这是主要目标之一。然而,这也必须考虑平衡各种资源,包括总 CPU 时间的需求,内存负载以及线程调度的开销。例如:获取自旋锁通常比阻塞锁所需的时间更短,但是通常也会浪费 CPU 时钟周期,并且造成内存竞争,所以使用的并不频繁。
while (synchronization state does not allow acquire) { enqueue current thread if not already queued; possibly block current thread; } dequeue current thread if it was queued;
release 操作如下:
1 2 3
update synchronization state; if (state may permit a blocked thread to acquire) unblock one or more queued threads;
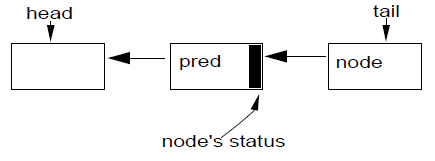
if(!tryAcquire(arg)) { node = create and enqueue newnode; pred = node's effective predecessor; while (pred is not head node || !tryAcquire(arg)) { if (pred's signal bit is set) pard() else compareAndSet pred's signal bit to true; pred = node's effective predecessor; } head = node; }
release操作:
1 2 3 4
if(tryRelease(arg) && head node's signal bit is set) { compareAndSet head's bit to false; unpark head's successor, if one exist }
Thanks to Dave Dice for countless ideas and advice during the development of this framework, to Mark Moir and Michael Scott for urging consideration of CLH queues, to David Holmes for critiquing early versions of the code and API, to Victor Luchangco and Bill Scherer for reviewing previous incarnations of the source code, and to the other members of the JSR166 Expert Group (Joe Bowbeer, Josh Bloch, Brian Goetz, David Holmes, and Tim Peierls) as well as Bill Pugh, for helping with design and specifications and commenting on drafts of this paper. Portions of this work were made possible by a DARPA PCES grant, NSF grant EIA-0080206 (for access to the 24way Sparc) and a Sun Collaborative Research Grant.
参考文献
Agesen, O., D. Detlefs, A. Garthwaite, R. Knippel, Y. S.Ramakrishna, and D. White. An Efficient Meta-lock for Implementing Ubiquitous Synchronization. ACM OOPSLA Proceedings, 1999.
Andrews, G. Concurrent Programming. Wiley, 1991.
Bacon, D. Thin Locks: Featherweight Synchronization for Java. ACM PLDI Proceedings, 1998.
Buhr, P. M. Fortier, and M. Coffin. Monitor Classification,ACM Computing Surveys, March 1995.
Craig, T. S. Building FIFO and priority-queueing spin locks from atomic swap. Technical Report TR 93-02-02,Department of Computer Science, University of Washington, Feb. 1993.
Gamma, E., R. Helm, R. Johnson, and J. Vlissides. Design Patterns, Addison Wesley, 1996.
Holmes, D. Synchronisation Rings, PhD Thesis, Macquarie University, 1999.
Magnussen, P., A. Landin, and E. Hagersten. Queue locks on cache coherent multiprocessors. 8th Intl. Parallel Processing Symposium, Cancun, Mexico, Apr. 1994.
Mellor-Crummey, J.M., and M. L. Scott. Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors. ACM Trans. on Computer Systems,February 1991
M. L. Scott and W N. Scherer III. Scalable Queue-Based Spin Locks with Timeout. 8th ACM Symp. on Principles and Practice of Parallel Programming, Snowbird, UT, June 2001.
这里主要的性能目标是可伸缩性,即在大部分情况下,即使,或特别在同步器有竞争的情况下,稳定地保证其效率。在理想的情况下,不管有多少线程正试图通过同步点,通过同步点的开销都应该是个常量。在某一线程被允许通过同步点但还没有通过的情况下,使其耗费的总时间最少,这是主要目标之一。然而,这也必须考虑平衡各种资源,包括总 CPU 时间的需求,内存负载以及线程调度的开销。例如:获取自旋锁通常比阻塞锁所需的时间更短,但是通常也会浪费 CPU 时钟周期,并且造成内存竞争,所以使用的并不频繁。
while (synchronization state does not allow acquire) { enqueue current thread if not already queued; possibly block current thread; } dequeue current thread if it was queued;
release 操作如下:
1 2 3
update synchronization state; if (state may permit a blocked thread to acquire) unblock one or more queued threads;
if(!tryAcquire(arg)) { node = create and enqueue newnode; pred = node's effective predecessor; while (pred is not head node || !tryAcquire(arg)) { if (pred's signal bit is set) pard() else compareAndSet pred's signal bit to true; pred = node's effective predecessor; } head = node; }
release操作:
1 2 3 4
if(tryRelease(arg) && head node's signal bit is set) { compareAndSet head's bit to false; unpark head's successor, if one exist }
Thanks to Dave Dice for countless ideas and advice during the development of this framework, to Mark Moir and Michael Scott for urging consideration of CLH queues, to David Holmes for critiquing early versions of the code and API, to Victor Luchangco and Bill Scherer for reviewing previous incarnations of the source code, and to the other members of the JSR166 Expert Group (Joe Bowbeer, Josh Bloch, Brian Goetz, David Holmes, and Tim Peierls) as well as Bill Pugh, for helping with design and specifications and commenting on drafts of this paper. Portions of this work were made possible by a DARPA PCES grant, NSF grant EIA-0080206 (for access to the 24way Sparc) and a Sun Collaborative Research Grant.
参考文献
Agesen, O., D. Detlefs, A. Garthwaite, R. Knippel, Y. S.Ramakrishna, and D. White. An Efficient Meta-lock for Implementing Ubiquitous Synchronization. ACM OOPSLA Proceedings, 1999.
Andrews, G. Concurrent Programming. Wiley, 1991.
Bacon, D. Thin Locks: Featherweight Synchronization for Java. ACM PLDI Proceedings, 1998.
Buhr, P. M. Fortier, and M. Coffin. Monitor Classification,ACM Computing Surveys, March 1995.
Craig, T. S. Building FIFO and priority-queueing spin locks from atomic swap. Technical Report TR 93-02-02,Department of Computer Science, University of Washington, Feb. 1993.
Gamma, E., R. Helm, R. Johnson, and J. Vlissides. Design Patterns, Addison Wesley, 1996.
Holmes, D. Synchronisation Rings, PhD Thesis, Macquarie University, 1999.
Magnussen, P., A. Landin, and E. Hagersten. Queue locks on cache coherent multiprocessors. 8th Intl. Parallel Processing Symposium, Cancun, Mexico, Apr. 1994.
Mellor-Crummey, J.M., and M. L. Scott. Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors. ACM Trans. on Computer Systems,February 1991
M. L. Scott and W N. Scherer III. Scalable Queue-Based Spin Locks with Timeout. 8th ACM Symp. on Principles and Practice of Parallel Programming, Snowbird, UT, June 2001.